A little over a year ago, I wrote the first of many posts arguing: if we want a healthy internet — and a healthy digital society — we need to make sure AI is trustworthy. AI, and the large pools of data that fuel it, are central to how computing works today. If we want apps, social networks, online stores and digital government to serve us as people — and as citizens — we need to make sure the way we build with AI has things like privacy and fairness built in from the get go.
Since writing that post, a number of us at Mozilla — along with literally hundreds of partners and collaborators — have been exploring the questions: What do we really mean by ‘trustworthy AI’? And, what do we want to do about it?
How do we collaboratively make trustworthy AI a reality?
Today, we’re kicking off a request for comment on v0.9 of Mozilla’s Trustworthy AI Whitepaper — and on the accompanying theory of change diagram that outlines the things we think need to happen. While I have fallen out of the habit, I have traditionally included a simple diagram in my blog posts to explain the core concept I’m trying to get at. I would like to come back to that old tradition here:
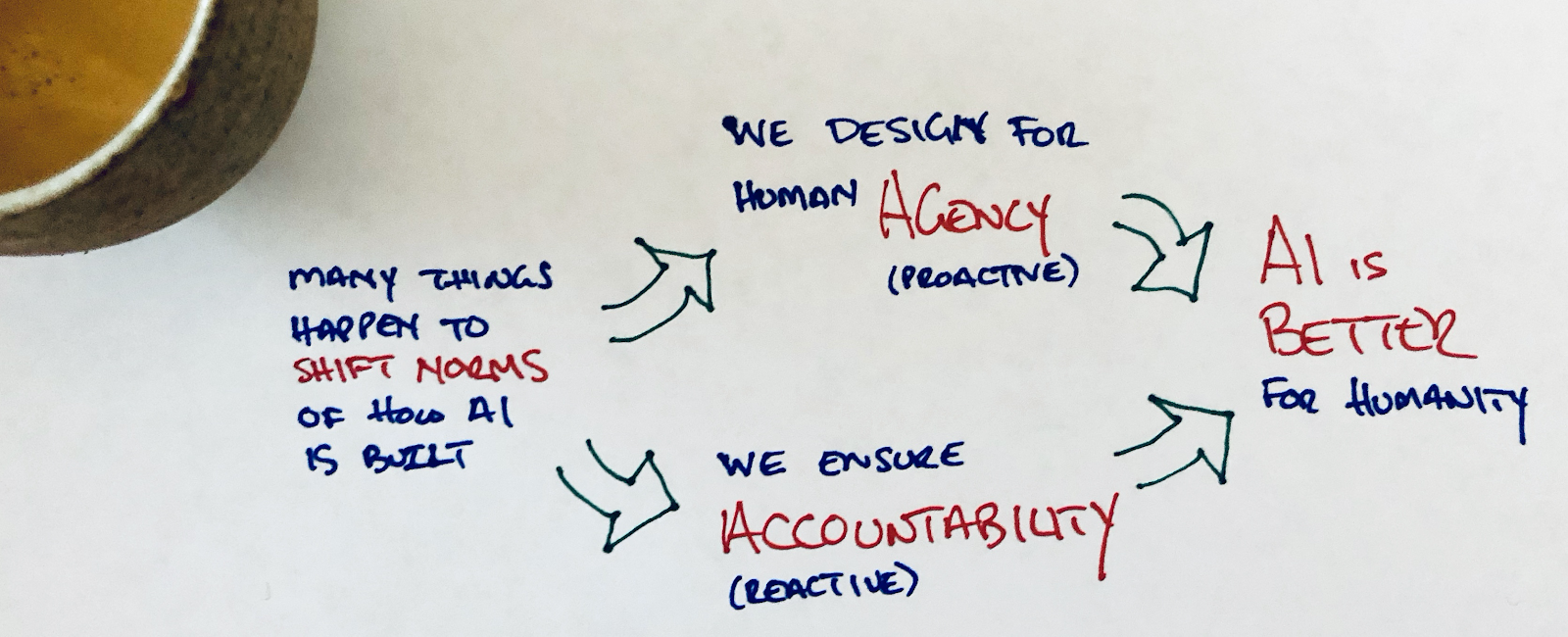
This cartoonish drawing gets to the essence of where we landed in our year of exploration: ‘agency’ and ‘accountability’ are the two things we need to focus on if we want the AI that surrounds us everyday to be more trustworthy. Agency is something that we need to proactively build into the digital products and services we use — we need computing norms and tech building blocks that put agency at the forefront of our design process. Accountability is about having effective ways to react if things go wrong — ways for people to demand better from the digital products and services we use everyday and for governments to enforce rules when things go wrong. Of course, I encourage you to look at the full (and fancy) version of our theory of change diagram — but the fact that ‘agency’ (proactive) and ‘accountability’ (reactive) are the core, mutually reinforcing parts of our trustworthy AI vision is the key thing to understand.
In parallel to developing our theory of change, Mozilla has also been working closely with partners over the past year to show what we mean by trustworthy AI, especially as it relates to consumer internet technology. A significant portion of our 2019 Internet Health Report was dedicated to AI issues. We ran campaigns to: pressure platforms like YouTube to make sure their content recommendations don’t promote misinformation; and call on Facebook and others to open up APIs to make political ad targeting more transparent. We provided consumers with a critical buying guide for AI-centric smart home gadgets like Amazon Alexa. We invested ~$4M in art projects and awarded fellowships to explore AI’s impact on society. And, as the world faced a near universal health crisis, we asked questions about how issues like AI, big data and privacy will play during — and after — the pandemic. As with all of Mozilla’s movement building work, our intention with our trustworthy AI efforts is to bias towards action and working with others.
A request for comments
It’s with this ‘act + collaborate’ bias in mind that we are embarking on a request for comments on v0.9 of the Mozilla Trustworthy AI Whitepaper. The paper talks about how industry, regulators and citizens of the internet can work together to build more agency and accountability into our digital world. It also talks briefly about some of the areas where Mozilla will focus, knowing that Mozilla is only one small actor in the bigger picture of shifting the AI tide.
Our aim is to use the current version of this paper as a foil for improving our thinking and — even more so — for identifying further opportunities to collaborate with others in building more trustworthy AI. This is why we’re using the term ‘request for comment’ (RFC). It is a very intentional hat tip to a long standing internet tradition of collaborating openly to figure out how things should work. For decades, the RFC process has been used by the internet community to figure out everything from standards for sharing email across different computer networks to best practices for defeating denial of service attacks. While this trustworthy AI effort is not primarily about technical standards (although that’s part of it), it felt (poetically) useful to frame this process as an RFC aimed at collaboratively and openly figuring out how to get to a world where AI and big data work quite differently than they do today.
We’re imagining that Mozilla’s trustworthy AI request for comment process includes three main steps, with the first step starting today.
Step 1: partners, friends and critics comment on the white paper
During this first part of the RFC, we’re interested in: feedback on our thinking; further examples to flesh out our points, especially from sources outside Europe and North America; and ideas for concrete collaboration.
The best way to provide input during this part of the process is to put up a blog post or some other document reacting to what we’ve written (and then share it with us). This will give you the space to flesh out your ideas and get them in front of both Mozilla (send us your post!) and a broader audience. If you want something quicker, there is also an online form where you can provide comments. We’ll be holding a number of online briefings and town halls for people who want to learn about and comment on the content in the paper — sign up through the form above to find out more. This phase of the process starts today and will run through September 2020.
Step 2: collaboratively map what’s happening — and what should happen
Given our focus on action, mapping out real trustworthy AI work that is already happening — and that should happen — is even more critical than honing frameworks in the white paper. At a baseline, this means collecting information about educational programs, technology building blocks, product prototypes, consumer campaigns and emerging government policies that focus on making trustworthy AI a reality.
The idea is that the ‘maps’ we create will be a resource for both Mozilla and the broader field. They will help Mozilla direct its fellows, funding and publicity efforts to valuable projects. And, they will help people from across the field see each other so they can share ideas and collaborate completely independently of our work.
Process-wise, these maps will be developed collaboratively by Mozilla’s Insights Team with involvement of people and organizations from across the field. Using a mix of feedback from the white paper comment process (step 1) and direct research, they will develop a general map of who is working on key elements of trustworthy AI. They will also develop a deeper landscape analysis on the topic of data stewardship and alternative approaches to data governance. This work will take place from now until November 2020.
Step 3: do more things together, and update the paper
The final — and most important — part of the process will be to figure out where Mozilla can do more to support and collaborate with others. We already know that we want to work more with people who are developing new approaches to data stewardship, including trusts, commons and coops. We see efforts like these as foundational building blocks for trustworthy AI. Separately, we also know that we want to find ways to support African entrepreneurs, researchers and activists working to build out a vision of AI for that continent that is independent of the big tech players in the US and China. Through the RFC process, we hope to identify further areas for action and collaboration, both big and small.
Partnerships around data stewardship and AI in Africa are already being developed by teams within Mozilla. A team has also been tasked with identifying smaller collaborations that could grow into something bigger over the coming years. We imagine this will happen slowly through suggestions made and patterns identified during the RFC process. This will then shape our 2021 planning — and will feed back into a (hopefully much richer) v1.0 of the whitepaper. We expect all this to be done by the end of 2020.
Mozilla cannot do this alone. None of us can.
As noted above: the task at hand is to collaboratively and openly figure out how to get to a world where AI and big data work quite differently than they do today. Mozilla cannot do this alone. None of us can. But together we are much greater than the sum of our parts. While this RFC process will certainly help us refine Mozilla’s approach and direction, it will hopefully also help others figure out where they want to take their efforts. And, where we can work together. We want our allies and our community not only to weigh in on the white paper, but also to contribute to the collective conversation about how we reshape AI in a way that lets us build — and live in — a healthier digital world.
PS. A huge thank you to all of those who have collaborated with us thus far and who will continue to provide valuable perspectives to our thinking on AI.
Your “Trustworthy AI” is a great concept, but hard to define with any precision. Like the person said “I can’t precisely define love, but I know it when I see it.” Which gets me to the bit about getting artists involved. If writing a novel or a TV script is art, then they provide a superb medium to contrast trustworthy and untrustworthy AI to Jane Doe and her family—and generate lots of laughs in the process.
There is one Sci-Fi series in which whenever the hero comes back to his apartment and taps into his home AI system, he is bombarded with incredibly banal whiny conversations between the IOT hot water heater and the washing machine with other self-centered appliances joining in.